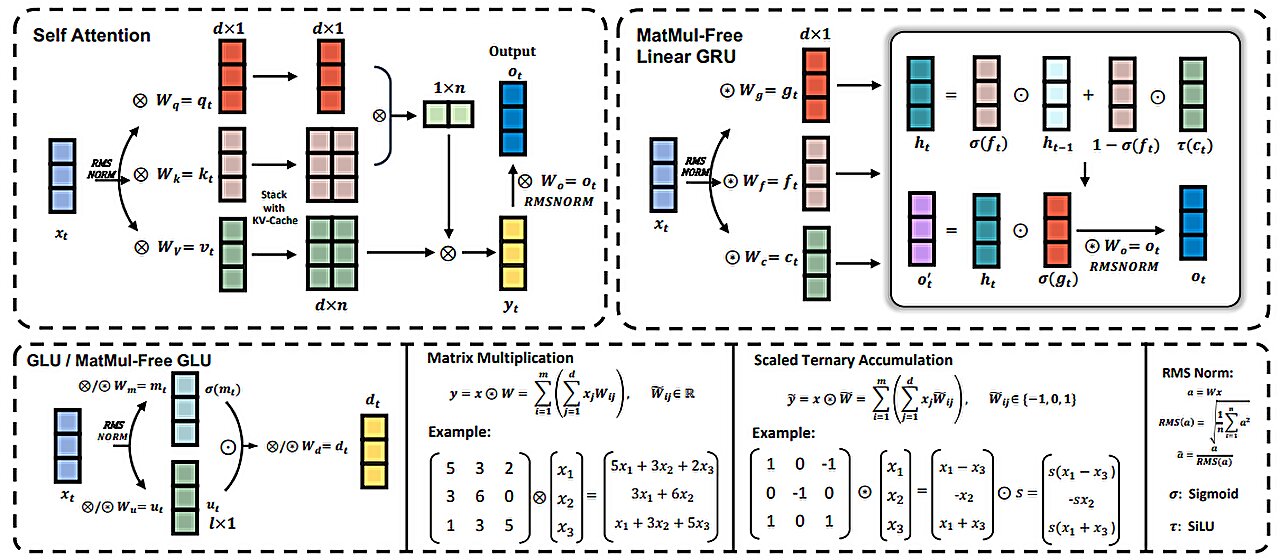
, the MatMul-free token mixer (top-right), and Ternary Accumulations. The MatMul-free LM employs a MatMul-free token mixer (MLGRU) and a MatMul-free channel mixer (MatMul-free GLU) to maintain the transformer-like architecture while reducing compute cost. Credit: arXiv (2024). DOI: 10.48550/arxiv.2406.02528")
A workforce of software program engineers on the College of California, working with one colleague from Soochow College and one other from LuxiTec, has developed a strategy to run AI language fashions with out utilizing matrix multiplication. The workforce has revealed a paper on the arXiv preprint server describing their new method and the way nicely it has labored throughout testing.
As the facility of LLMs similar to ChatGPT has grown, so too have the computing sources they require. A part of the method of operating LLMs entails performing matrix multiplication (MatMul), the place information is mixed with weights in neural networks to supply possible finest solutions to queries.
Early on, AI researchers found that graphics processing items (GPUs) had been ideally suited to neural community functions as a result of they’ll run a number of processes concurrently—on this case, a number of MatMuls. However now, even with large clusters of GPUs, MatMuls have grow to be bottlenecks as the facility of LLMs grows together with the variety of individuals utilizing them.
On this new research, the analysis workforce claims to have developed a strategy to run AI language fashions with out the necessity to perform MatMuls—and to do it simply as effectively.
To realize this feat, the analysis workforce took a brand new method to how information is weighted—they changed the present technique that depends on 16-bit floating factors with one which makes use of simply three: {-1, 0, 1} together with new features that perform the identical kinds of operations because the prior technique.
In addition they developed new quantization strategies that helped enhance efficiency. With fewer weights, much less processing is required, ensuing within the want for much less computing energy. However additionally they radically modified the way in which LLMs are processed through the use of what they describe as a MatMul-free linear gated recurrent unit (MLGRU) within the place of conventional transformer blocks.
In testing their new concepts, the researchers discovered {that a} system utilizing their new method achieved a efficiency that was on par with state-of-the-art techniques presently in use. On the similar time, they discovered that their system used far much less computing energy and electrical energy than is usually the case with conventional techniques.
Extra info:
Rui-Jie Zhu et al, Scalable MatMul-free Language Modeling, arXiv (2024). DOI: 10.48550/arxiv.2406.02528
© 2024 Science X Community
Quotation:
Software program engineers develop a strategy to run AI language fashions with out matrix multiplication (2024, June 26)
retrieved 28 June 2024
from https://techxplore.com/information/2024-06-software-ai-language-matrix-multiplication.html
This doc is topic to copyright. Other than any honest dealing for the aim of personal research or analysis, no
half could also be reproduced with out the written permission. The content material is supplied for info functions solely.


